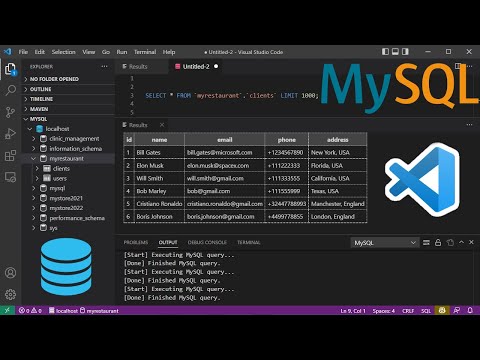
Argument Description --partitioned-access Whether every mapper acts on a subset of knowledge slices of a table or all Default is "false" for traditional mode and "true" for direct mode. This option specifies the error threshold per mapper whereas transferring knowledge. If the number of errors encountered exceed this threshold then the job will fail. Specifies the listing the place Netezza exterior desk operation logs are stored on the hadoop filesystem. Logs are saved underneath this directory with one listing for the job and sub-directories for every task quantity and try. Specifies whether the system truncates strings to the declared storage and masses the information. Specifies whether or not control characters (ASCII chars ) can be allowed to be a half of char/nchar/varchar/nvarchar columns. By default, sqoop-export appends new rows to a desk; each enter report is remodeled into an INSERT statement that adds a row to the target database desk. This mode is primarily supposed for exporting information to a new, empty table supposed to receive these outcomes. Property Description mapred.reduce.tasks Number of reduce tasks for staging. Pgbulkload.bin Path of the pg_bulkoad binary put in on every slave nodes. Pgbulkload.check.constraints Specify whether or not CHECK constraints are checked through the loading. Pgbulkload.parse.errors The maximum mumber of ingored data that trigger errors throughout parsing, encoding, filtering, constraints checking, and knowledge type conversion. Error information are recorded within the PARSE BADFILE. The default worth is INFINITE. Pgbulkload.duplicate.errors Number of ingored records that violate distinctive constraints. Duplicated data are recorded in the DUPLICATE BADFILE on DB server.

Pgbulkload.filter Specify the filter function to transform every row in the enter file. See the pg_bulkload documentation to know how to write FILTER capabilities. Pgbulkload.clear.staging.desk Indicates that any information present within the staging desk can be dropped. SequenceFiles are a binary format that store particular person data in custom record-specific knowledge types. Most features of the import, code technology, and export processes could be custom-made. For databases, you can management the specific row vary or columns imported. You can specify explicit delimiters and escape characters for the file-based representation of the info, as nicely as the file format used. You also can control the category or bundle names utilized in generated code. Subsequent sections of this document clarify tips on how to specify these and different arguments to Sqoop. Professional MySQL to Oracle DB transformation utility fully support all MySQL database attributes, data varieties, key constraints including main, ... During conversion of priceless enterprise report recordsdata from MySQL database to Oracle server format. PostgreSQL "has more features" than other database administration techniques . Also, PostgreSQL is extensible "because its operation is catalog-driven". In other phrases, it doesn't just store information about tables and columns; it allows you to outline knowledge varieties, index sorts, and functional languages. When two expressions with different SQL Server knowledge sorts are mixed together by an operator, they could not always play properly collectively. They may be automatically, aka implicitly, transformed into the acceptable data type, making the generated combination higher, without raising any errors.

But you could face other circumstances, during which you should manually, aka explicitly, perform an acceptable information type conversion, so as to keep away from the combination error. To carry out the explicit information conversion, SQL Server supplies us with three major conversion features; CAST, CONVERT and PARSE. The primary concern on this article is to match the performance of those conversion methods and see which technique is the most effective to use. Before going via the efficiency comparability between the three conversion features, we are going to briefly describe these capabilities. This means it may possibly update the view without needing to question the source information. For instance, should you create a summary desk that counts teams of rows, and you add a row to the supply desk, Flexviews simply increments the corresponding group by one. The same approach works for different combination functions, similar to SUM() and AVG(). Computing with deltas is far more environment friendly than studying the data from the source desk. MySQL's storage engine API works by copying rows between the server and the storage engine in a row buffer format; the server then decodes the buffer into columns. But it can be expensive to show the row buffer into the row data construction with the decoded columns. MyISAM's fixed row format actually matches the server's row format precisely, so no conversion is required. However, MyISAM's variable row format and InnoDB's row format all the time require conversion. The cost of this conversion is determined by the variety of columns. If you're planning for hundreds of columns, remember that the server's efficiency traits shall be a bit completely different. Netezza connector supports an optimized data switch facility utilizing the Netezza external tables function. Each map duties of Netezza connector's import job will work on a subset of the Netezza partitions and transparently create and use an external desk to transport knowledge. Similarly, export jobs will use the exterior table to push data quick onto the NZ system. Direct mode doesn't assist staging tables, upsert choices and so forth. You can specify the number of map tasks to use to perform the import through the use of the -m or --num-mappers argument.

Each of those arguments takes an integer value which corresponds to the diploma of parallelism to employ. Some databases may even see improved efficiency by increasing this worth to 8 or sixteen. Likewise, don't enhance the degree of parallism higher than that which your database can fairly help. Connecting one hundred concurrent shoppers to your database might enhance the load on the database server to some extent the place performance suffers as a result. Since the two are so related, many SQL newbies (and some extra experienced users!) marvel what the difference is. The main difference is that CONVERT() can also convert the character set of knowledge into another character set. Hence, CAST() ought to be your goto conversion function, except you have to convert a personality set. MySQL JDBC Connector is supporting upsert functionality using argument--update-mode allowinsert. MySQL will attempt to insert new row and if the insertion fails with duplicate distinctive key error it'll update appropriate row as an alternative. As a outcome, Sqoop is ignoring values laid out in parameter --update-key, nevertheless person must specify at least one valid column to turn on update mode itself. The possibility --hcatalog-storage-stanza can be used to specify the storage format of the newly created table. The value specified for this feature is assumed to be a valid Hive storage format expression. It shall be appended to the create tablecommand generated by the HCatalog import job as a part of automatic desk creation. Any error within the storage stanza will cause the table creation to fail and the import job will be aborted. A by-product of the import process is a generated Java class which can encapsulate one row of the imported desk. This class is used during the import process by Sqoop itself. The Java supply code for this class can be supplied to you, to be used in subsequent MapReduce processing of the data. This class can serialize and deserialize knowledge to and from the SequenceFile format. These talents let you shortly develop MapReduce applications that use the HDFS-stored records in your processing pipeline.

You are also free to parse the delimiteds document data your self, utilizing some other instruments you like. Data migration is a course of of choosing, getting ready, extracting, transforming, and applying the info from one database to a different database. Once you choose a kind, ensure you use the identical type in all associated tables. The sorts ought to match exactly, including properties corresponding to UNSIGNED. Mixing different data sorts could cause performance problems, and even when it doesn't, implicit sort conversions throughout comparisons can create hard-to-find errors. These might even crop up a lot later, after you've forgotten that you're evaluating different data varieties. CHAR is useful if you want to store very quick strings, or if all the values are nearly the identical length. For instance, CHAR is an efficient selection for MD5 values for person passwords, that are always the same size. CHAR is also better than VARCHAR for information that's changed incessantly, because a fixed-length row is not prone to fragmentation. The HCatalog table should be created before utilizing it as part of a Sqoop job if the default desk creation options are not adequate. All storage formats supported by HCatalog can be utilized with the creation of the HCatalog tables. This makes this function readily adopt new storage formats that come into the Hive project, corresponding to ORC information. You can control the number of mappers independently from the variety of information present within the directory. By default, Sqoop will use 4 duties in parallel for the export process. This will not be optimum; you will want to experiment with your personal specific setup. The --num-mappers or -marguments control the number of map duties, which is the degree of parallelism used. You can use the --hive-drop-import-delims choice to drop those characters on import to offer Hive-compatible textual content data. Alternatively, you need to use the --hive-delims-replacement option to replace these characters with a user-defined string on import to provide Hive-compatible textual content information.
These options should solely be used should you use Hive's default delimiters and shouldn't be used if different delimiters are specified. Avro knowledge files are a compact, environment friendly binary format that provides interoperability with applications written in different programming languages. Avro also helps versioning, so that when, e.g., columns are added or faraway from a desk, previously imported knowledge information could be processed together with new ones. By default, the import process will use JDBC which supplies an inexpensive cross-vendor import channel. Some databases can carry out imports in a extra high-performance trend by using database-specific knowledge movement tools. For example, MySQL offers the mysqldump software which may export knowledge from MySQL to different systems in a short time. By supplying the --direct argument, you are specifying that Sqoop should attempt the direct import channel. Data from a relational database system or a mainframe into HDFS. The input to the import process is both database desk or mainframe datasets. For databases, Sqoop will learn the desk row-by-row into HDFS. For mainframe datasets, Sqoop will learn data from each mainframe dataset into HDFS. The output of this import course of is a set of files containing a copy of the imported table or datasets. These information could additionally be delimited text recordsdata , or binary Avro or SequenceFiles containing serialized record data. This sets the default storage engine upon connecting to the database. After your tables have been created, you should remove this selection as it provides a question that's solely wanted during table creation to every database connection. The out there instructions to perform that are; CAST, CONVERT and PARSE. In this article, we described briefly the differences between these three capabilities, how to use it and eventually evaluate their performance.
SQL Server provides us with other ways to transform the SQL Server information type of an expression into another data kind. That's not to say that migrating from Oracle to Postgres just isn't an concerned course of. In MySQL, we will convert between information sorts using the CAST() and CONVERT() features. In at present's blog, we'll discover ways to make use of each capabilities using examples for example their usage. As a part of the 8.zero migration effort, we decided to standardize on utilizing row-based replication . Some 8.0 features required RBR, and it simplified our MyRocks porting efforts. While most of our MySQL replica units had been already using RBR, these still running statement-based replication could not be easily converted. These reproduction sets often had tables with none high cardinality keys. Switching completely to RBR had been a aim, however the lengthy tail of work wanted to add major keys was often prioritized decrease than other tasks. Oracle to MySQL converter permits users to do oblique conversion and get more control over the process. Following this way, this system converts Oracle information into a neighborhood MySQL dump file as a substitute of shifting it to MySQL server immediately. This dump file incorporates MySQL statements to create all tables and to fill them with the info.Click right here to discover methods to import dump file into MySQL database. TIMESTAMP also has particular properties that DATETIME doesn't have. By default, MySQL will set the primary TIMESTAMP column to the present time whenever you insert a row with out specifying a worth for the column. MySQL additionally updates the first TIMESTAMP column's value by default when you replace the row, until you assign a worth explicitly within the UPDATE statement.

You can configure the insertion and update behaviors for any TIMESTAMP column. Finally, TIMESTAMP columns are NOT NULL by default, which is different from every other data sort. The following table offers a list of the entire knowledge sorts that cx_Oracle knows how to fetch. The center column provides the sort that's returned in thequery metadata. The last column provides the type of Python object that's returned by default. MySQL version comes with an updated listing of reserved phrases and you need to verify that you just don't use them in your database. You need to check foreign key constraint names, they cannot be longer than 64 characters. Some choices for sql_mode have been removed thus you should be certain to do not use them. As we talked about, there's an extensive listing of things to test. This example takes the files in /results/bar_data and injects their contents in to the bar table in the foo database on db.instance.com. Sqoop performs a set of INSERT INTO operations, without regard for existing content. If Sqoop attempts to insert rows which violate constraints in the database , then the export fails. NoteSupport for staging data prior to pushing it into the vacation spot desk is not at all times out there for --direct exports.

It is also not out there when export is invoked using the --update-key choice for updating existing information, and when saved procedures are used to insert the data. It is greatest to check the Section 25, "Notes for particular connectors" section to validate. This could also be higher-performance than the usual JDBC codepath. Details about use of direct mode with every particular RDBMS, installation necessities, out there options and limitations may be present in Section 25, "Notes for particular connectors". MariaDB 10.1 and above does not support MySQL 5.7's packed JSON objects. MariaDB follows the SQL standard and shops the JSON as a traditional TEXT/BLOB. If you need to replicate JSON columns from MySQL to MariaDB, you should store JSON objects in MySQL in a TEXT column or use statement based mostly replication. If you would possibly be utilizing JSON columns and wish to upgrade to MariaDB, you possibly can either convert the JSON columns to TEXT or use mysqldump to copy these tables to MariaDB. In MariaDB JSON strings are regular strings and compared as strings. Postgres helps ANSI SQL standard SQL syntax and information types, whereas Oracle doesn't help the same normal; additionally, it contains some non-ANSI SQL syntaxes. Using instruments, unsupported objects should be identified and then converted manually with Postgres-supported syntax or function workarounds. That version included compelling options like writeset-based parallel replication and a transactional information dictionary that supplied atomic DDL assist. For us, transferring to 8.0 would additionally convey in the 5.7 options we had missed, together with Document Store.

Version 5.6 was approaching finish of life, and we wished to stay active throughout the MySQL group, especially with our work on the MyRocks storage engine. Enhancements in 8.0, like prompt DDL, may pace up MyRocks schema adjustments, however we wanted to be on the 8.0 codebase to use it. Given the advantages of the code update, we determined emigrate to eight.0. We're sharing how we tackled our 8.0 migration project — and a few of the surprises we found within the process. When we initially scoped out the project, it was clear that transferring to eight.0 could be much more troublesome than migrating to 5.6 or MyRocks. The next step within the migration course of is to transform the captured model of the database to an Oracle-specific mannequin. The captured mannequin accommodates knowledge sorts, naming schemes etc. outlined by your database vendor; this now must be transformed to Oracle formats. Once the migration has completed, you'll have the ability to return the Captured Database Objects node and rerun the wizard from this level to convert some or all the objects again. SQLines SQL Converter tool permits you to convert database schema , queries and DML statements, views, saved procedures, capabilities and triggers from Oracle to MySQL. BLOB and TEXT are string data varieties designed to retailer massive amounts of data as either binary or character strings, respectively. These sorts are helpful when you should store binary information and want MySQL to compare the values as bytes as a substitute of characters. The benefit of byte-wise comparisons is more than just a matter of case insensitivity. MySQL actually compares BINARY strings one byte at a time, based on the numeric value of each byte. As a result, binary comparisons may be much less complicated than character comparisons, so they're quicker. NoteSqoop's dealing with of date and timestamp information varieties does not store the timezone.
